July 25, 2024
Coding with Llama 3.1, new DeepSeek Coder & Mistral Large
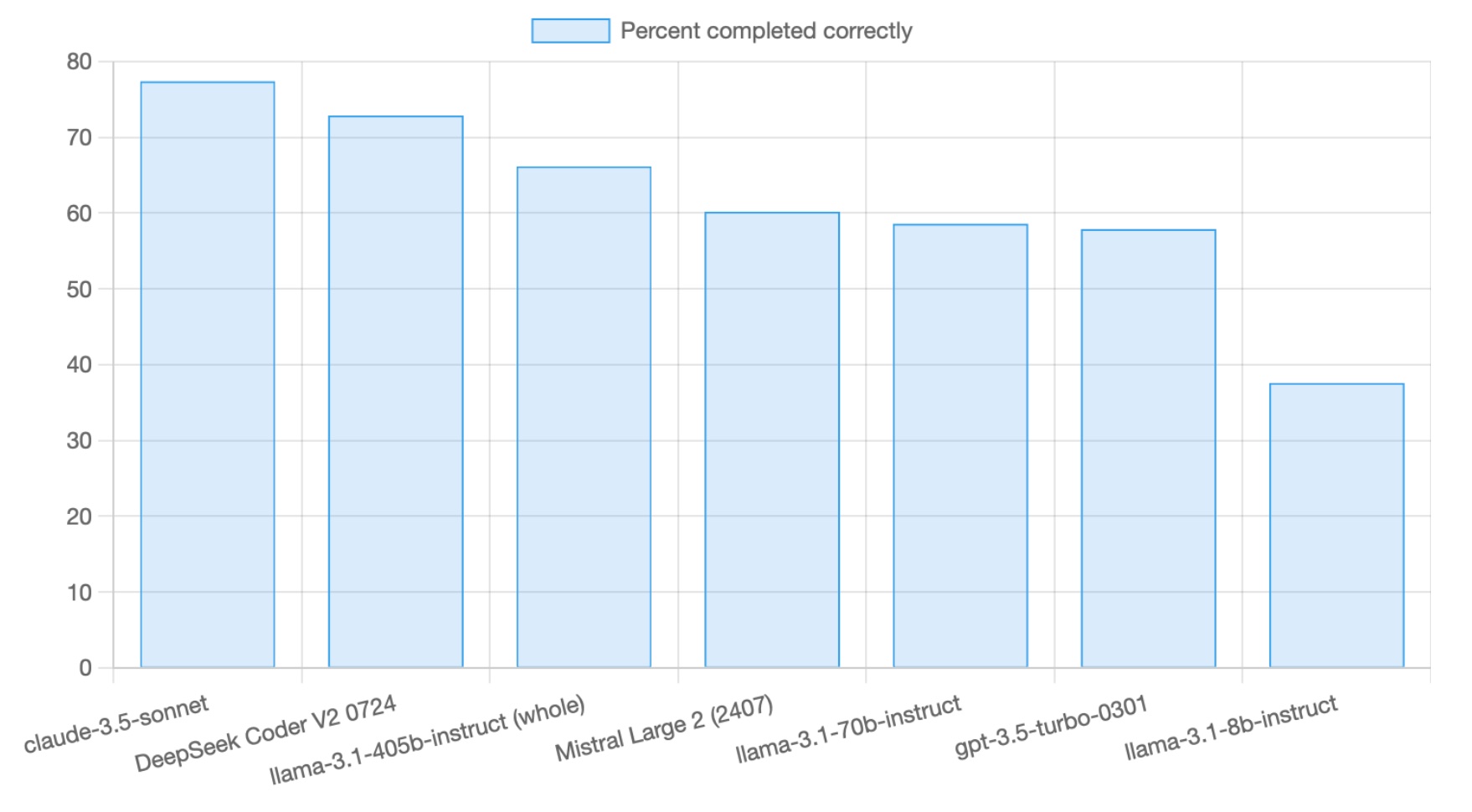
Five noteworthy models have been released in the last few days, with a wide range of code editing capabilities. Here are their results from aider’s code editing leaderboard with Claude 3.5 Sonnet and the best GPT-3.5 model included for scale.
- 77% claude-3.5-sonnet
- 73% DeepSeek Coder V2 0724
- 66% llama-3.1-405b-instruct
- 60% Mistral Large 2 (2407)
- 59% llama-3.1-70b-instruct
- 58% gpt-3.5-turbo-0301
- 38% llama-3.1-8b-instruct
You can code with all of these models using aider like this:
$ python -m pip install -U aider-chat
# Change directory into a git repo to work on
$ cd /to/your/git/repo
$ export DEEPSEEK_API_KEY=your-key-goes-here
$ aider --model deepseek/deepseek-coder
$ export MISTRAL_API_KEY=your-key-goes-here
$ aider --model mistral/mistral-large-2407
$ export OPENROUTER_API_KEY=your-key-goes-here
$ aider --model openrouter/meta-llama/llama-3.1-405b-instruct
$ aider --model openrouter/meta-llama/llama-3.1-70b-instruct
$ aider --model openrouter/meta-llama/llama-3.1-8b-instruct
See the installation instructions and other documentation for more details.
DeepSeek Coder V2 0724
DeepSeek Coder V2 0724 was by far the biggest surprise and strongest code editing model, coming in 2nd on the leaderboard. It can efficiently edit code with SEARCH/REPLACE, unlike the prior DeepSeek Coder version. This unlocks the ability to edit large files.
This new Coder version got 73% on the benchmark, very close to Sonnet’s 77% but 20-50X less expensive!
LLama 3.1
Meta released the Llama 3.1 family of models, which have performed well on many evals.
The flagship Llama 3.1 405B instruct only secured #7 on aider’s leaderboard, well behind frontier models like Claude 3.5 Sonnet & GPT-4o.
The 405B model can use SEARCH/REPLACE to efficiently edit code, but with a decrease in the benchmark score. When using this “diff” editing format, its score dropped from 66% to 64%.
The smaller 70B model was competitive with GPT-3.5, while the 8B model lags far behind. Both seem unable to reliably use SEARCH/REPLACE to edit files. This limits them to editing smaller files that can fit into their output token limit.
Mistral Large 2 (2407)
Mistral Large 2 (2407) scored only 60% on aider’s code editing benchmark. This puts it just ahead of the best GPT-3.5 model. It doesn’t seem able to reliably use SEARCH/REPLACE to efficiently edit code, which limits its use to small source files.